In one of my last posts, I was getting started with a home server using a Raspberry PI 4. Since then, I have upgraded the setup and the hardware as well.
The RPi had 8GB of RAM, but it was not very stable for a home server. By stability, I mean: stable storage, faster RAM, faster processor, more ports, etc Since starting with the home server with RPi, I wanted to have some regularly used services rather than just hosting whatever I like. For example, in the last post, I said I hosted memos for note-taking, but it didn’t work. I didn’t see myself using it very much (not at all, actually). I understood that this is kind of a trial-and-error method, but I need to have a few services that I actually use regularly.
I wrote down the ones which I would actually need in order to de-google (inspired by PewDiePie and Linus - I still cannot believe PDP is into self-hosting and Linux).
Photos management: My wife loves taking photos, and multiple photos of same and different poses. So, of-course the media storage is growing exponentially. Self-hosting photos is a challenging task, the harder parts being having a backup of photos, photos being easily accessible, and sync with the native photos app.
All of the photos were previously on iCloud. So, the service
Needs to have an iOS app to sync whatever photos I take on my iPhone.
Needs to be fast.
I then found Immich, which ticked both the above boxes. Although it’s still in very early stages, I was ok with that after trying it once.
When I tried running immich with all other services, RPi was starting to struggle, which I think might be mainly because of the ML sidecar it provides to recognize faces. With the new hardware, I think Immich is one of the best tools for this job.
Media management: A Few days back, I was watching a movie on Prime, and an Ad suddenly appeared out of nowhere. I was surprised since I have paid Amazon for Prime Video, and now I am getting ads? After further investigation, I came to know they have introduced Ads that we have to pay extra to get rid of. This triggered me a bit, and since I was already thinking of self-hosting, I decided this will definitely be on my to-do list.
The ARR stack
This is a popular stack among self-hosters. This stack helps one find and download movies easily with the help of a torrent client. This stack (mainly) consists of:
Sonarr: Tv show manager
Radarr: Movie manager
Prowlarr: Indexers to get torrents from
Bazarr: Subtitles manager
For the download client, I use deluge. The flow looks something like - User adds a list of indexers to use in Prowlarr, then the user searches for TV shows/movies in Sonarr/Radarr, and downloads the specific media, which adds the torrent to the connected download client. The download client then finished downloading, Sonarr/Radarr then picks it up and puts the downloaded media in a specific directory (more on this later). If the subtitles aren’t downloaded or you are not satisfied with the subs, you can request Bazarr for subs, and it downloads and puts them into the media directory where the movie is located.
Jellyfin is the main service where TV shows or Movies are viewed. Both Sonarr and Radarr mount the Jellyfin path as a Docker service. When the media is downloaded, it is immediately moved to the Jellyfin-mounted path, which is then used by Jellyfin.
Drive replacement: There are multiple reasons to not use drive:
Monthly subscription for higher storage (which is fair, but still, I didn’t want to keep paying)
No data privacy with Google - Google scans all the files, and I didn’t want that, especially with the rise of AI.
I was looking into Filestash, which has a decent shareability feature. It was good for short-term data storage for me, but for the long term, it was the right choice. I still have Filestash running, but just for media viewing.
Also tried NextCloud, it’s very bulky and slow and written in PHP (which isn’t bad in itself, but for this use case, I wanted something fast)
Seafile
I decided to go with Seafile. To start with, it’s really fast and has an iOS app as well, which is great. Also has great user management and many other options.
The only thing I was thinking before starting to use Seafile was the way it stores data. It does not store the media directly, but it breaks the data into pieces and stores them. This has its own pros and cons:
Duplicate files don’t take extra space. Since it’s being hashed (git like), it’s easy to find duplicates.
It’s very hard to migrate data from Seafile. Seafile gives a Fuse option to mount it as a drive. Still, it’s very hard to directly migrate the data without Seafile’s initial dependency.
For me, this was OK. Since my main goal was to have a stable service and for it to be fast. Seafile does both, and does it very well. So, I did go with Seafile, which I did not regret (at least until now). I even tried PaperlessNgx, but it still didn’t fit for me.
In order to share links, I had to make this service publicly exposed. Did that using Cloudflare tunnels to make this process a bit safer.
Password management: I was very skeptical of self-hosted password managers, mainly because of any error from my side and not being able to access the passwords. I still went with Vaultwarden when using RPi and still don’t regret that. Although with RPi, I didn’t really use the password manager that well. Now, I have been actively using it for every site I visit, and even to generate random passwords.
The case that I was worried about didn’t even exist since I can read the passwords from Vaultwarden even when the home server is down, I can only not write to it, which seems fair. This motivates me to follow a proper setup and decrease downtime (importantly, when I’m not at home), which I call Downtime Discipline.
I get this beautiful autocomplete, which is self-hosted on my server. Knowing that the data is safe with you gives you a greater level of satisfaction than something that any privately owned company promises.
- YouTube archivals: I wanted to keep a copy of any YouTube video that I feel is great (and videos which might be taken down for some reason), hence archiving YouTube videos is a concept of its own. TubeArchivist is a great self-hostable tool to download videos. Every tool of this kind is a yt-dl wrapper.
I have an unlisted playlist for this setup. I can just add videos to that playlist and rescan the library in Tubearchivist, which should download the added videos. It’s a great tool that I don’t always use, but still sometimes serves my use case.
- Bookmarks Manager: I used to manage bookmarks with my browser (Brave) itself, and I didn’t use the same browser on my phone. Bookmarking was something I always wanted to have a solution for myself, but I was too lazy to solve it. Since I had a need, I looked out for options in the market. Found Linkding to be a very nice solution for me.
It even has an iOS app (unofficial), which is pretty nice. Bookmarking is not just saving links but also saving the content inside the links since the site may go down at some point, and I don’t want my bookmarks to point at dead links. Linkding automatically archives websites, either as a local HTML file or on the Internet Archive.
I still use Nginx-Proxy-Manager for routing subdomains to respective ports with https certs.
Hardware specs

The RPi I used had 8GB RAM and an ARM processor. I was running headless Raspbian on it, which was light enough to keep it running. Since I have gotten serious with home servers, I needed a real computer (not a new one necessarily).
I did not want it to be very bulky since it might take up a lot of power. After searching for a few days on the internet, I found a few used small form factor PCs specifically Lenovo M720s. It had 4 RAM slots, 128 GB NVMe SSD, Intel i5 9th gen 4.4Ghz processor. I filled up the RAM slots with 16 x 4 cards totaling 64GB. I also bought an 1TB external SSD (bought the next version of this ssd) (not sure if external is the perfect choice, but it works great!)
I came with Windows! The first thing I did after bringing it home was remove Windows and install headless Debian on it.
Monitoring
The goal of monitoring is to know if any service is down or if the homelab itself is down. It was quite tricky since this is all happening inside a local network; it’s not possible for me to know if my lab is down.
Now, the notification center is slack. I created a new Slack account and a couple of channels in it to be notified.
I decided to go with 2 parts:
Service monitoring: Gatus pings all services in intervals and sends a notification to the Slack channel when any service doesn’t respond with a 200 code after 3 attempts.
Previously, I used Uptime-kuma for this (without the notifications). The problem with uptime-kuma is that it does not run on a config file. Everything must be done via the GUI, which I did not like at all.
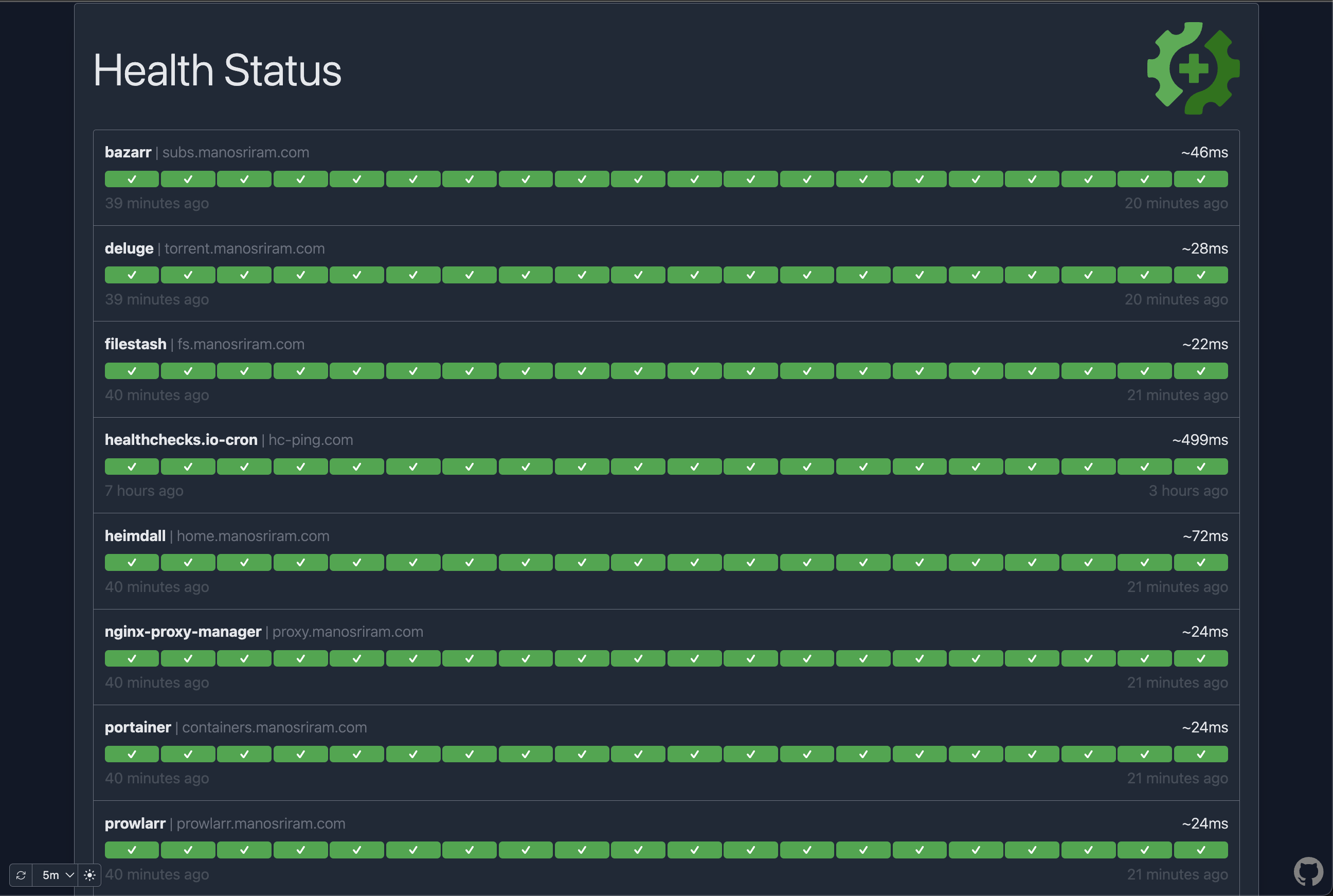
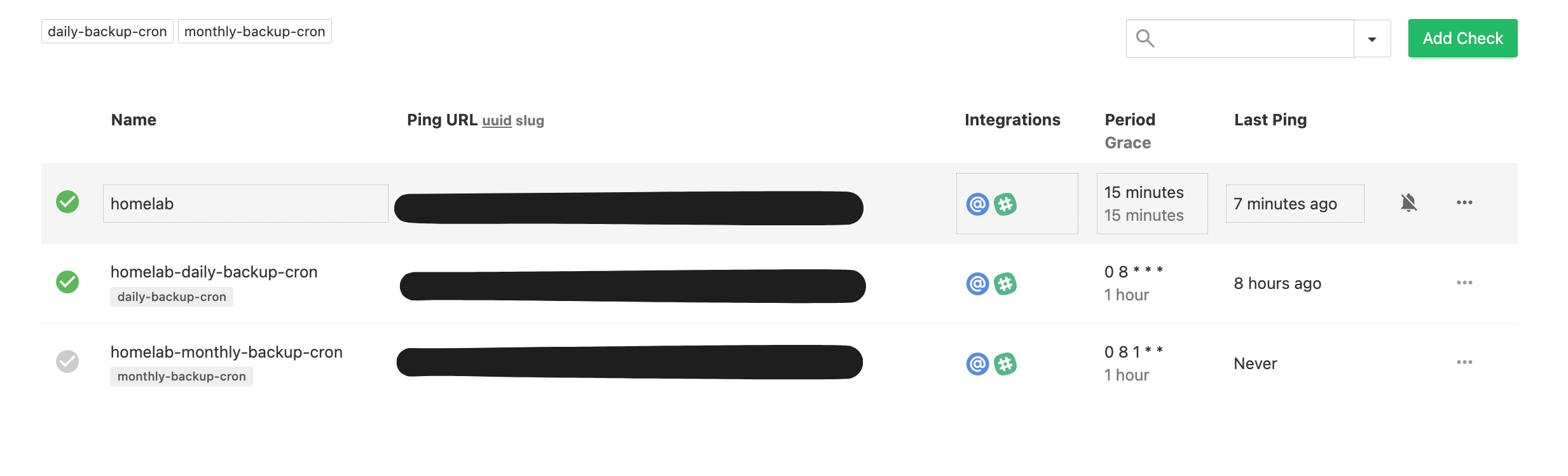
Lab monitoring: All services are now being monitored except Gatus (lol). I would not know if Gatus went down. To solve this, I added a check to ping for a healthchecks.io monitor every 15 minutes with a grace period of an extra 15 minutes.
If healthchecks.io doesn’t receive the request within that time, it sends a notification to the Slack channel as well as an email.
I was using ntfy before trying this flow, but I didn’t want to self-host a notification service for some reason.
Also, I have ufw enabled with limited ports open for the services that are running. I have a file with a list of port numbers. I run a script to add them to UFW. So, whenever I create a new service, I have to add the port via the script. Otherwise, it just won’t allow the requests to come in.
Backups
This was a very critical process and needed a flow that I could rely on. First, I needed to store the backups somewhere. AWS was good, but felt a little pricier since I just want cold storage. Then, I looked at Backblaze B2, and it fit perfectly. B2 charges about 0.001$/GB.
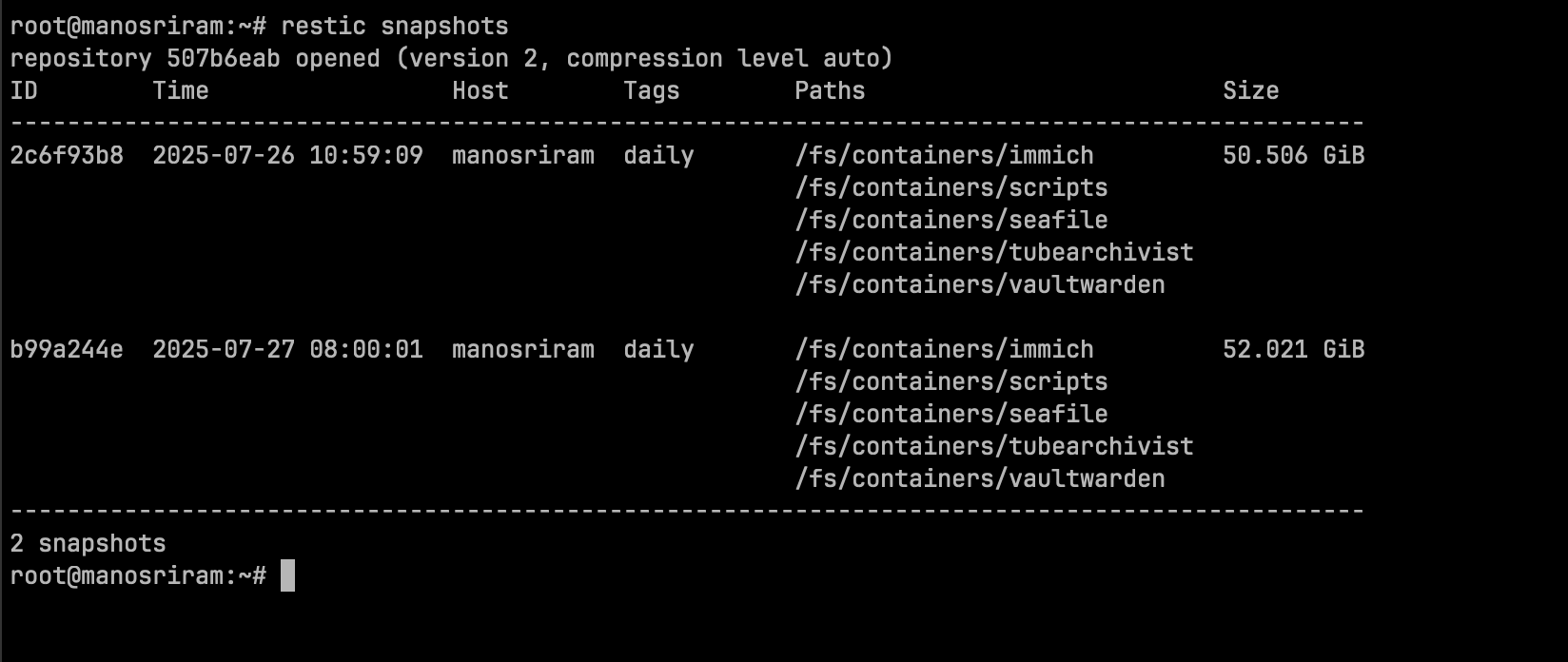
The idea is to run a daily backup job and a monthly backup job. Restic was a great tool for this kind of process.
The con, which I said for Seafile, ie, it hashes and stores the files, so it’s easier to see duplicate files; Restic follows the same process here, which turns out to be a huge advantage.
Whenever I run a backup, after the initial backup, it only writes the new changes, and the old ones aren’t rewritten.
I run 2 cron jobs, one for daily and another for monthly. Every day at 8 am, a daily backup job is run. Every 1st day of the month, the monthly backup job is run.
I run the restic backup command with a daily/monthly tag to differentiate between them. After running, I run the forget command, with flags --tag daily --keep-daily 30. This keeps the last 30days’ backup. For the monthly backup, --tag monthly --keep-monthly 1 does the job.
All of this is done by interacting with the B2 cloud. Both the cron job pings healthchecks.io after finishing the job. If any job doesn’t run on schedule, I get a Slack message saying so.
This is not exactly the 3-2-1 backup strategy, but this is safe enough for me (at least for now).
All of this setup from scratch would not be possible without the help of the subreddits referenced below. There are a lot of articles and helpful people who write about their setup and best practices to follow. I cannot thank these anonymous people enough.
I try to explain all of this homelab setup to my non-tech wife, she cares deeply so she nods along, but I’m pretty sure she is just nodding so that I would stop talking about it.
Writing this from a coffee shop. Thanks for reading!